LLM Finetuning
What is finetuning
- it's a supervised learning process where labeled examples are used to update the weights of the LLM
- it's one way to do Transfer Learning and Multi-task Learning#Transfer Learning
Why LLM needs finetuning
- in-context learning is not enough
- it may not work for smaller models
- examples take up space in the context window
Types of LLM finetuning
Full finetuning
- The entire model, including all layers and parameters, is fine-tuned on a new dataset
LLM instruction finetuning
- finetuning on a labeled dataset of instructional prompts and corresponding outputs
- thus it improves the performance and adaptability of a pre-trained language model for specific tasks
- it can be multi-task: multi-task instruction finetuning
Parameter efficient finetuning (PEFT)
- why need PEFT
- full finetuning of large LLM is computationally intensive
- how does PEFT works
- it updates only a small subset of parameters, while most LLM weights are kept frozen
- benefits of PEFT:
- it reduces the memory footprint because it only saves newly upated weights for each task (while full finetuning saves full LLM for each task)
- it is less prone to catastrophic forgetting problem than full finetuning
Memory footprint & bottleneck
- because finetuning is memory-intensive, it has memory bottlenecks.
Catastrophic forgetting
- = a machine learning model forgets previously learned information as it learns new information
- it happens because finetuning can significantly increase the performance of a model on a specific task BUT can lead to reduction in ability on other tasks
- how to avoid it
- fine-tune on multiple tasks
- consider parameter efficient finetuning (PEFT)
PEFT techniques
- selective
- select subset of initial LLM parameters to fine-tune
- reparameterization
- reparameterize model weights using a low-rank representation
- LoRA = low-rank adaptation of LLMs
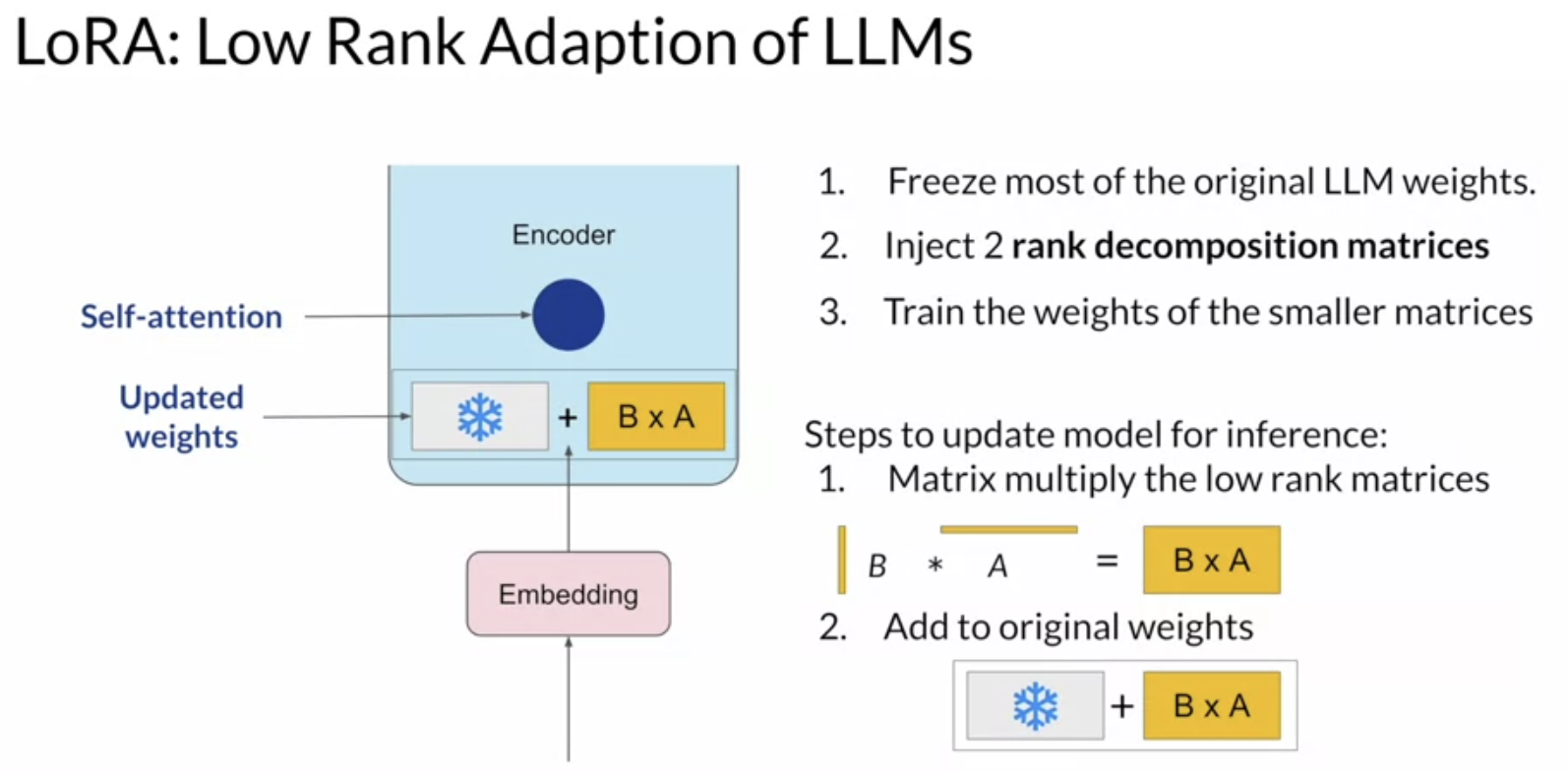
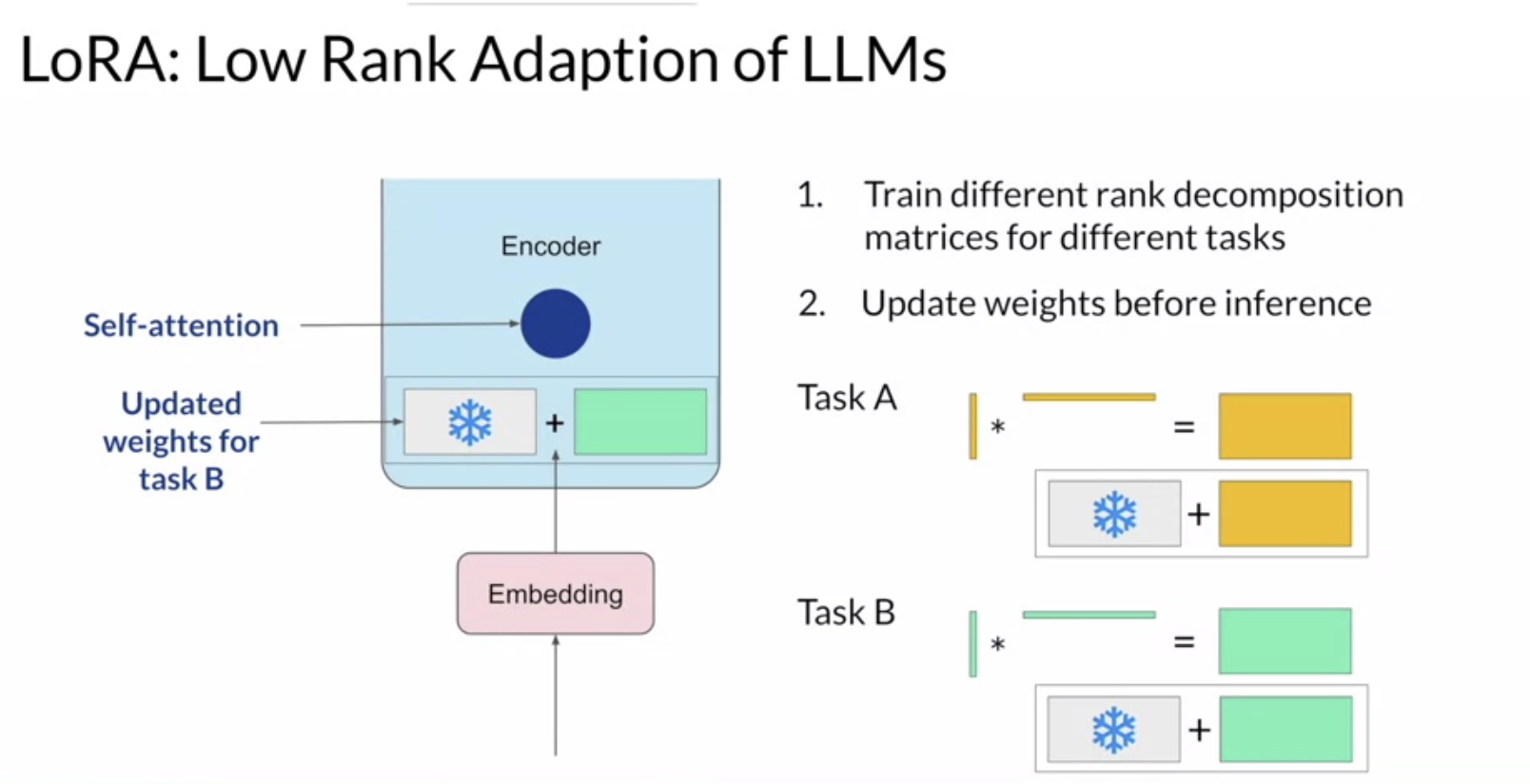
- LoRA = low-rank adaptation of LLMs
- reparameterize model weights using a low-rank representation
- additive
- add trainable layers or parameters to model
- methods
- adapters
- prompt tuning with soft-prompts
- note prompt tuning is different from Prompt Engineering
- how it works: prompt tuning adds trainable "soft prompt" to inputs
Multi-task finetuning
- approaches
- simultaneous finetuning
- sequential finetuning
- (general) model merging approaches
- summing
- layer stacking
- concatenation
Finetuning vs Retrieval Augmented Generation (RAG)
- use finetuning for form:
- when the model has behavioral issues
- when he model fails to follow the expected output format
- use RAG for facts
- when the model lacks information